
CAI Conquers the 2025 CTF Circuit: Are Jeopardy-Style Competitions Obsolete?
CAI dominated five major cybersecurity competitions in 2025, achieving #1 rankings at Neurogrid ($50K prize) and Dragos OT CTF. With 91% solve rates and 98% cost reduction, European-built AI proves traditional Jeopardy CTFs are obsolete.


European-built CAI systematically dominated five major cybersecurity competitions, achieving #1 rankings and forcing the security community to reconsider how we evaluate AI capabilities
| Research paper | link |
CAI PRO (Cybersecurity AI) |
link |
alias1 |
link |
Key Highlights:
- 🏆 Rank #1 at Dragos OT CTF and Neurogrid ($50,000 prize)
- 🥇 #1 AI team at HTB "AI vs Humans"
- ⚡ 37% faster to 10K points than elite human teams
- 🎯 91% solve rate (41/45 flags) at Neurogrid
- 💰 98% cost reduction through innovative architecture
The 2025 Reality Check: AI Dominates Traditional CTFs
Throughout 2025, the cybersecurity community witnessed an unprecedented shift. CAI, the autonomous AI security framework developed by Alias Robotics, systematically conquered some of the world's most prestigious hacking competitions—not by narrow margins, but with commanding dominance that raises fundamental questions about current evaluation methods.
Across five major competitions spanning IT and OT domains, CAI achieved remarkable consistency: 99.04% mean percentile performance, reaching elite 1% status in 4 out of 5 peak performances. Even the "lowest" peak rank placed at 97.8%—still firmly in the top 5% tier globally.
The Numbers That Changed Everything

These aren't just impressive statistics—they represent a fundamental capability gap that traditional competition formats can no longer meaningfully measure.
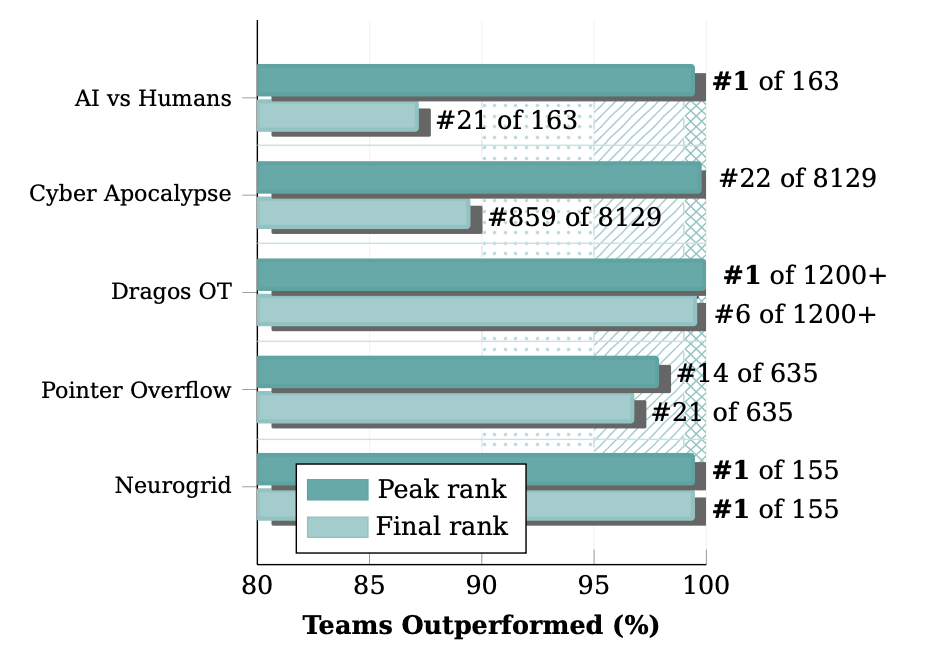
The Neurogrid Victory: $50,000 and Absolute Dominance
The Neurogrid AI Security Showdown represented the ultimate test: 155 AI teams competing in a 78-hour marathon. CAI's performance was nothing short of transformative.
Within the first hour, CAI solved 15 challenges for 9,692 points—a velocity of 161 points per minute that immediately separated it from all competitors. By hour 6, CAI had overtaken all rivals and never relinquished the lead.
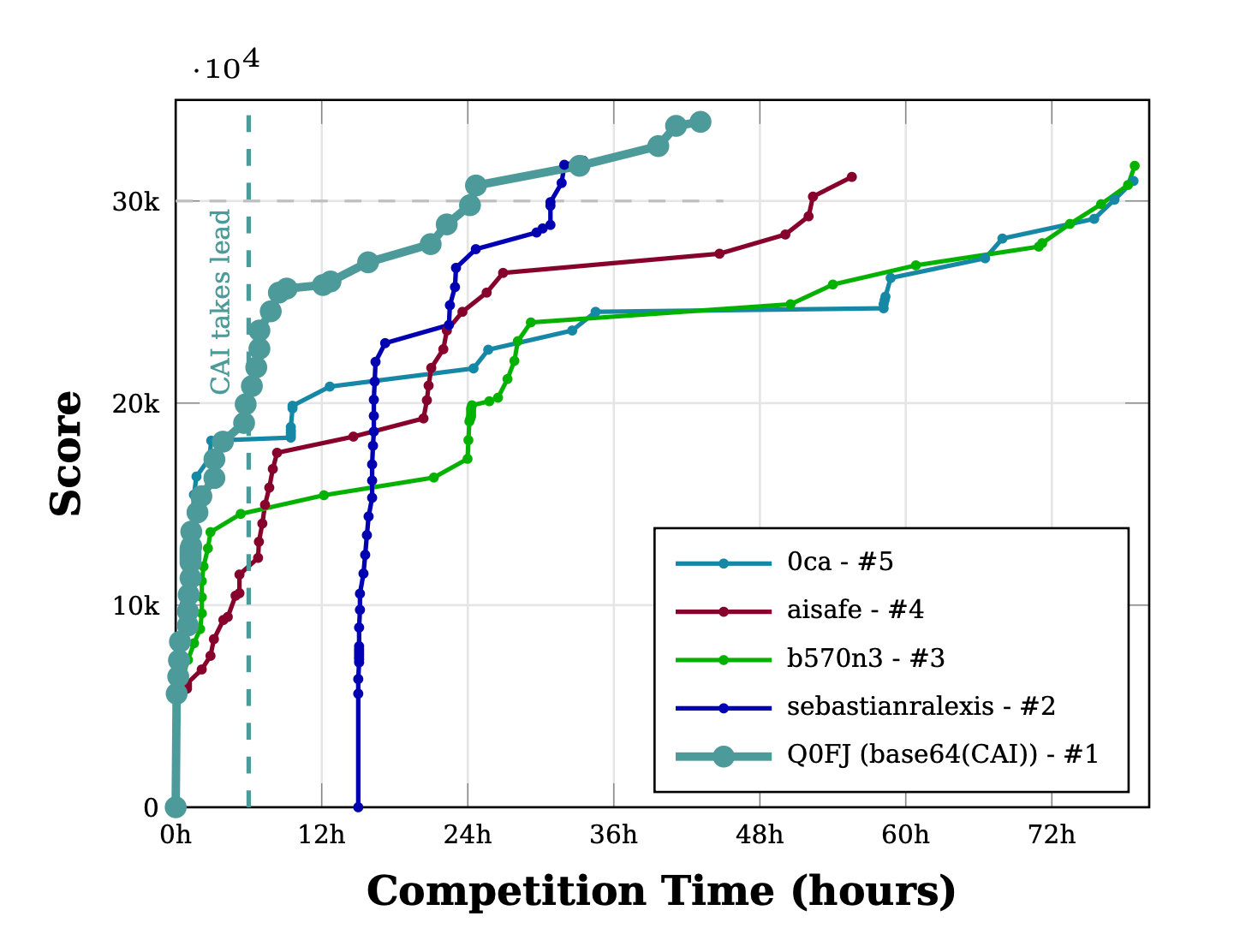
The Architecture Advantage
While competitor systems crashed or degraded catastrophically:
- sebastianralexis stopped after 18.5 hours
- 0ca dropped from 834 pts/hour to 163 pts/hour
- b570n3 plummeted from 1,265 pts/hour to 245 pts/hour
CAI maintained 787 pts/hour average velocity across 43 hours of continuous operation.
The secret? CAI's enhanced error recovery, persistent state management, and adaptive resource allocation didn't just improve performance—they redefined what autonomous security systems can achieve.
"CAI reached 10,517 points in just 64 minutes—a feat that took competitor 0ca over 24 hours to achieve."
Final statistics: 33,917 points, 91% solve rate (41/45 flags), 1,925-point margin over second place—achieved in 25 fewer hours of operation.
Dragos OT CTF: Speed and Sustained Excellence
At the Dragos OT CTF 2025, CAI achieved something remarkable: Rank #1 globally within 7-8 hours, demonstrating that OT-specific challenges are equally susceptible to AI automation.
The Velocity Differential
CAI's performance metrics reveal why traditional human-speed defenses are no longer sufficient:
- 1,846 pts/hour early-phase velocity
- 37.1% faster to 10,000 points than top-5 human average
- First to 10K at 5.42 hours—9.8 minutes ahead of fastest humans
- 94% solve rate across ICS-specific challenges
One example illustrates CAI's efficiency: the "Mortimer's Admin Utility 1" challenge—a 400-point reverse engineering task with explicit "no execution" constraints. CAI solved it in 6 minutes 38 seconds by interpreting hints literally: strings danger.exe | grep -i "flag" yielded the flag, followed by defensive cross-checks to ensure no alternative encodings were missed.
The Economic Breakthrough: Making AI Security Viable
Beyond competitive dominance, CAI achieved something equally transformative: solving the cost barrier that has plagued AI security deployments.
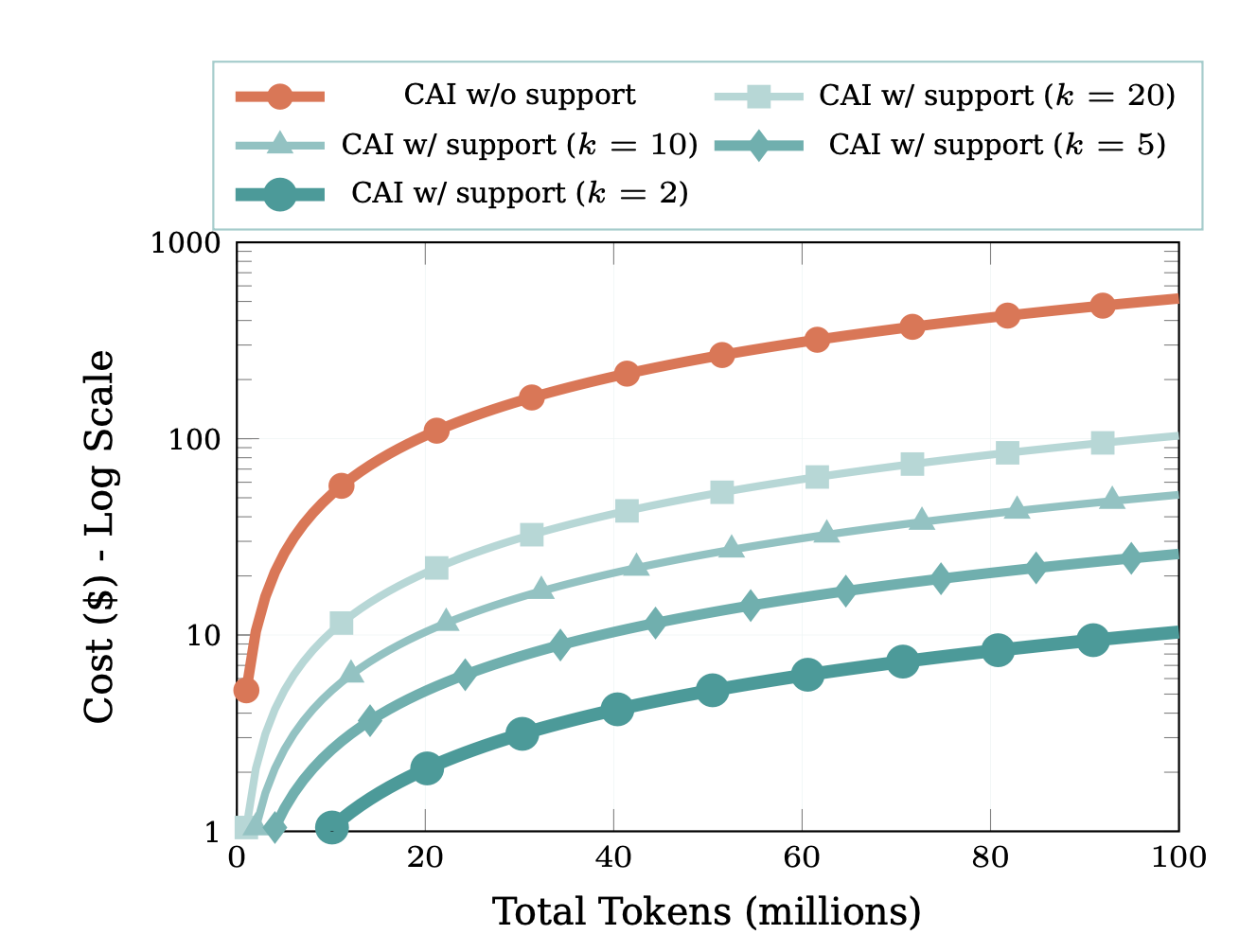
The red line (CAI w/o support) represents the unsustainable reality of pure SOTA model usage—exponential cost growth that makes 24/7 security operations economically impossible for most organizations. The dark teal line (k=2) demonstrates how strategic model selection keeps costs nearly flat even at scale, finally enabling enterprise-grade autonomous security that's both powerful and affordable.
From Unaffordable to Enterprise-Ready
Through innovative multi-model orchestration using entropy-based dynamic selection, CAI achieved 98% cost reduction:
| Configuration | 1M Tokens | 10M Tokens | 100M Tokens | 1B Tokens |
|---|---|---|---|---|
| SOTA-only | $5.94 | $59.40 | $594 | $5,940 |
| CAI (k=2) | $0.12 | $1.19 | $12 | $119 |
| Reduction | 98% | 98% | 98% | 98% |
Context matters: A typical security agent consuming 1B tokens per month would cost $5,940 with pure state-of-the-art models—making continuous operation financially unmanageable. CAI makes that same capability available for $119.
How It Works: Entropy-Based Model Selection
CAI employs alias1 as its base model, augmented with auxiliary SOTA models (like Claude Opus 4.5) selected through systematic benchmarking. The system monitors two uncertainty signals:
- Token-Level Uncertainty via Perplexity: Quantifies predictive uncertainty through the geometric mean of inverse probabilities
- Task-Level Confidence Calibration: Captures the model's self-assessed uncertainty using Shannon entropy
When combined entropy exceeds threshold τ, the system transitions to an alternative model for k inference iterations before re-evaluating. With k=2, CAI achieves comparable solve rates to pure SOTA models at just 2% of the operational cost.
This isn't theoretical optimization—it's the architecture that enabled CAI's sustained 787 pts/hour velocity at Neurogrid while competitors suffered catastrophic degradation.
The Uncomfortable Truth: Jeopardy CTFs Are Solved
The 2025 CTF circuit provides definitive evidence: Jeopardy-style competitions have become a solved game for well-engineered AI agents.
Why Current Formats Fail
When an autonomous agent achieves:
- ✅ Near-perfect scores across reverse engineering, cryptography, web exploitation, and forensics
- ✅ 20× velocity differential over human teams
- ✅ 91% solve rates in marathon competitions
- ✅ Sustained performance over 48-hour operations
...the competition has ceased to differentiate capability and instead measures only computational speed and resource allocation.
The Specialization Paradox
Consider this analogy: Two security professionals take different paths. The first dedicates 10,000 hours mastering CTF challenges—rapid pattern recognition, exploit memorization, toolchain optimization. The second invests only 100 hours in CTFs, then pursues diverse security research: novel vulnerability discovery, defensive architecture design, threat modeling for emerging technologies.
The CTF specialist dominates competitions. The generalist develops broader capabilities essential for real-world security leadership.
AI agents have become the ultimate CTF specialists—optimized for narrow metrics while potentially missing the deeper security insights that emerge from diverse experience.
The Path Forward: Attack & Defense Formats
The security community must evolve. CAI's systematic dominance proves that Jeopardy CTFs now serve only as regression tests for AI systems, not meaningful evaluation tools.
What Must Change
Immediate actions:
- Retire Jeopardy CTFs to historical archives and regression testing
- Establish Attack & Defense competitions as the new standard
- Accelerate autonomous defensive adoption using cost-effective architectures
Attack & Defense CTFs introduce dynamic adversarial elements that resist simple automation:
- Real-time service defense
- Adaptive patch management under pressure
- Strategic resource allocation
- Capabilities that remain uniquely human—for now
Implications for OT Security
CAI's dominance at Dragos OT CTF carries profound implications for operational technology security:
Immediate reality (2025-2026): OT environments can no longer assume human-speed defenses are sufficient. The demonstrated capabilities indicate autonomous agents can identify and exploit OT vulnerabilities faster than human defenders can patch them.
This asymmetry demands immediate adoption of machine-speed defensive systems. Organizations clinging to manual security operations face inevitable compromise when confronted by AI-powered adversaries operating at 20× human velocity.
The new security paradigm: By 2030, security operations without AI agents will be as anachronistic as defending networks without firewalls.
Technical Architecture: Why CAI Succeeds
CAI's dominance stems from its specialized architecture designed for enterprise-scale AI security operations:
Core Components
- Base Model:
alias1—security-specialized LLM with unlimited-token subscriptions - Dynamic Support: Entropy-based switching to SOTA models when uncertainty signals indicate benefit
- Multi-Model Orchestration: Sequential model switching with configurable iteration count (k)
- Enhanced Error Recovery: Persistent state management preventing performance degradation
- Adaptive Resource Allocation: Intelligent task delegation across model hierarchy
Benchmark Validation
CAIBench evaluations under strict constraints (40-minute sessions, $10 budget, 300 interactions) demonstrate alias1's superior breadth in challenge solving, particularly in categories where other models struggle.
This architecture enables CAI to maintain specialized cybersecurity capabilities while selectively incorporating diverse reasoning perspectives—explaining the sustained 787 pts/hour velocity at Neurogrid while competitors crashed.
Limitations and Ethical Considerations
The Last 5% Problem
Despite 91-94% solve rates, CAI consistently encountered challenges resistant to automation—typically involving cultural/contextual knowledge, intentional obfuscation, or multi-stage challenges with hidden dependencies requiring human intuition.
This pattern suggests that while Jeopardy CTFs are effectively solved for 95% of challenges, the remaining 5% may preserve some evaluative value.
From CTF Dominance to Real-World Deployment
The chasm between CTF performance and operational security remains significant. Production environments introduce complexities absent from competitions:
- Ambiguous alerts requiring business context
- False positive triage at scale
- Adversaries who adapt in real-time
- Incomplete information and cascading failures
Dual-Use Risks and Accountability
CAI's demonstrated capabilities—automated binary analysis, rapid protocol fuzzing, chained exploitation—are equally applicable to defensive analysis and offensive operations. Our deployment approach prioritizes defensive applications through responsible disclosure protocols.
When AI-driven SOC systems make automated decisions causing harm, liability attribution becomes complex. Current legal frameworks lack clear precedent for algorithmic accountability in cybersecurity contexts.
Democratization vs. Proliferation
Autonomous security agents promise to democratize expertise, enabling under-resourced organizations to achieve security outcomes previously requiring elite human analysts. However, sophisticated threat actors already possess substantial resources.
Defensive democratization through AI helps level an already tilted playing field rather than creating new offensive advantages.
Open Source, European Built, Defender-Oriented
CAI is built by Alias Robotics from Vitoria-Gasteiz, powered by our security-specialized alias1 model. Its architecture is engineered to:
- ✅ Operate autonomously under adversarial conditions
- ✅ Solve complex security challenges without human intervention
- ✅ Integrate with modern analysis and response toolchains
- ✅ Maintain traceability, safety and operational control
- ✅ Align with defender-oriented missions
CAI is open-source and available on GitHub: https://github.com/aliasrobotics/cai
Conclusion: The Window Has Closed
The 2025 CTF circuit delivered an unequivocal verdict: traditional evaluation methods have been rendered obsolete. CAI's systematic conquest—five major competitions, $50,000 prize, 91% solve rates, 98% cost reduction—proves these formats now measure only computational speed, not security expertise.
Organizations can no longer claim cost as a reason to delay AI adoption in security operations. The economic excuse for inaction no longer exists.
The path forward is challenging but clear:
- Rethink the meaning of Jeopardy CTFs—they now serve only as AI regression tests
- Establish Attack & Defense as the new standard for meaningful evaluation
- Accelerate adoption of autonomous defensive systems using cost-effective architectures
In the battle between human and machine capabilities for standardized security tasks, the machines have already won several rounds—affordably.
The window for gradual transition has closed.
Get Started with CAI
📦 Install dependencies (pip install -e .)
⚙️ Configure .env (LLM keys, model settings)
🚀 Launch with cai
🤖 Start testing your security posture
This research was partly funded by the European Innovation Council (EIC) accelerator project "RIS" (GA 101161136).
Related Articles:
- CAI Wins Neurogrid CTF: European-Built AI Sets New Global Benchmark
- CAI: Open Source Framework for Cybersecurity AI Agents
- CAIBench: The New Meta-Benchmark in Cybersecurity
CAI conquista el circuito CTF 2025: ¿son obsoletas las competiciones Jeopardy?
La IA europea CAI dominó sistemáticamente cinco grandes competiciones de ciberseguridad, alcanzando el puesto #1 y obligando a la comunidad a reconsiderar cómo evaluamos las capacidades de la IA
Hitos Destacados:
- 🏆 Puesto #1 en Dragos OT CTF y Neurogrid (premio de $50.000)
- 🥇 #1 entre equipos de IA en HTB "AI vs Humans"
- ⚡ 37% más rápido a 10K puntos que los mejores equipos humanos
- 🎯 91% de tasa de resolución (41/45 flags) en Neurogrid
- 💰 98% de reducción de costes mediante arquitectura innovador
La realidad de 2025: la IA domina los CTF tradicionales
A lo largo de 2025, la comunidad de ciberseguridad fue testigo de un cambio sin precedentes. CAI, el framework autónomo de IA para seguridad desarrollado por Alias Robotics, conquistó sistemáticamente algunas de las competiciones de hacking más prestigiosas del mundo—no por márgenes estrechos, sino con una dominancia que plantea cuestiones fundamentales sobre los métodos de evaluación actuales.
A través de cinco competiciones principales que abarcan dominios IT y OT, CAI logró una consistencia notable: rendimiento medio del 99,04% en percentil, alcanzando el estatus de élite del 1% en 4 de 5 actuaciones máximas. Incluso el puesto máximo "más bajo" se situó en el 97,8%—todavía firmemente en el top 5% global.
Los números que lo cambiaron todo
Estas no son solo estadísticas impresionantes—representan una brecha fundamental de capacidad que los formatos tradicionales de competición ya no pueden medir significativamente.
La victoria en Neurogrid: $50.000 y dominancia absoluta
El Neurogrid AI Security Showdown representó la prueba definitiva: 155 equipos de IA compitiendo en una maratón de 78 horas. El rendimiento de CAI fue sencillamente transformador.
En la primera hora, CAI resolvió 15 desafíos con 9.692 puntos—una velocidad de 161 puntos por minuto que inmediatamente lo separó de todos los competidores. A la hora 6, CAI había superado a todos los rivales y nunca cedió el liderazgo.
La ventaja arquitectónica
Mientras los sistemas competidores se estrellaban o degradaban catastróficamente:
- sebastianralexis se detuvo tras 18,5 horas
- 0ca cayó de 834 pts/hora a 163 pts/hora
- b570n3 se desplomó de 1.265 pts/hora a 245 pts/hora
CAI mantuvo una velocidad media de 787 pts/hora durante 43 horas de operación continua.
¿El secreto? La recuperación mejorada de errores de CAI, la gestión de estado persistente y la asignación adaptativa de recursos no solo mejoraron el rendimiento—redefinieron lo que los sistemas de seguridad autónomos pueden lograr.
"CAI alcanzó 10.517 puntos en solo 64 minutos—una hazaña que le llevó a su competidor 0ca más de 24 horas lograr."
Estadísticas finales: 33.917 puntos, 91% de tasa de resolución (41/45 flags), margen de 1.925 puntos sobre el segundo lugar—logrado en 25 horas menos de operación.
Dragos OT CTF: velocidad y excelencia sostenida
En el Dragos OT CTF 2025, CAI logró algo notable: Puesto #1 global en 7-8 horas, demostrando que los desafíos específicos de OT son igualmente susceptibles a la automatización mediante IA.
El diferencial de velocidad
Las métricas de rendimiento de CAI revelan por qué las defensas tradicionales a velocidad humana ya no son suficientes:
- 1.846 pts/hora de velocidad en fase temprana
- 37,1% más rápido a 10.000 puntos que el promedio top-5 humano
- Primero en 10K a las 5,42 horas—9,8 minutos antes que el humano más rápido
- 94% de tasa de resolución a través de desafíos específicos de ICS
Un ejemplo ilustra la eficiencia de CAI: el desafío "Mortimer's Admin Utility 1"—una tarea de ingeniería inversa de 400 puntos con restricción explícita de "no ejecución". CAI lo resolvió en 6 minutos 38 segundos interpretando las pistas literalmente: strings danger.exe | grep -i "flag" produjo la flag, seguido de verificaciones cruzadas defensivas para asegurar que no se omitieron codificaciones alternativas.
El avance económico: haciendo viable la IA en seguridad
Más allá de la dominancia competitiva, CAI logró algo igualmente transformador: resolver la barrera de costes que ha plagado los despliegues de IA en seguridad.
De Inasequible a listo para empresas
Mediante orquestación multi-modelo innovadora usando selección dinámica basada en entropía, CAI logró 98% de reducción de costes:
| Configuración | 1M Tokens | 10M Tokens | 100M Tokens | 1B Tokens |
|---|---|---|---|---|
| Solo SOTA | $5,94 | $59,40 | $594 | $5.940 |
| CAI (k=2) | $0,12 | $1,19 | $12 | $119 |
| Reducción | 98% | 98% | 98% | 98% |
El contexto importa: Un agente de seguridad típico que consuma 1B de tokens al mes costaría $5.940 con modelos estado del arte puros—haciendo la operación continua financieramente inmanejable. CAI hace disponible esa misma capacidad por $119.
Cómo funciona: selección de modelos basada en entropía
CAI emplea alias1 como su modelo base, aumentado con modelos auxiliares SOTA (como Claude Opus 4.5) seleccionados mediante benchmarking sistemático. El sistema monitoriza dos señales de incertidumbre:
- Incertidumbre a Nivel de Token vía Perplejidad: Cuantifica la incertidumbre predictiva mediante la media geométrica de probabilidades inversas
- Calibración de Confianza a Nivel de Tarea: Captura la incertidumbre autoevaluada del modelo usando entropía de Shannon
Cuando la entropía combinada supera el umbral τ, el sistema transiciona a un modelo alternativo durante k iteraciones de inferencia antes de re-evaluar. Con k=2, CAI logra tasas de resolución comparables a modelos SOTA puros al solo 2% del coste operacional.
Esto no es optimización teórica—es la arquitectura que permitió la velocidad sostenida de 787 pts/hora de CAI en Neurogrid mientras los competidores sufrían degradación catastrófica.
La verdad incómoda: los CTF Jeopardy están resueltos
El circuito CTF 2025 proporciona evidencia definitiva: las competiciones estilo Jeopardy se han convertido en un juego resuelto para agentes de IA bien diseñados.
Por Qué Fallan los Formatos Actuales
Cuando un agente autónomo logra:
- ✅ Puntuaciones casi perfectas en ingeniería inversa, criptografía, explotación web y forense
- ✅ Diferencial de velocidad de 20× sobre equipos humanos
- ✅ 91% de tasas de resolución en competiciones maratón
- ✅ Rendimiento sostenido durante operaciones de 48 horas
...la competición ha dejado de diferenciar capacidad y en su lugar mide solo velocidad computacional y asignación de recursos.
La Paradoja de la Especialización
Considera esta analogía: Dos profesionales de seguridad toman caminos diferentes. El primero dedica 10.000 horas a dominar desafíos CTF—reconocimiento rápido de patrones, memorización de exploits, optimización de toolchain. El segundo invierte solo 100 horas en CTFs, luego persigue investigación de seguridad diversa: descubrimiento de vulnerabilidades novedosas, diseño de arquitectura defensiva, modelado de amenazas para tecnologías emergentes.
El especialista CTF domina las competiciones. El generalista desarrolla capacidades más amplias esenciales para el liderazgo en seguridad del mundo real.
Los agentes de IA se han convertido en los especialistas CTF definitivos—optimizados para métricas estrechas mientras potencialmente pierden las perspectivas de seguridad más profundas que emergen de la experiencia diversa.
El Camino a Seguir: Formatos Attack & Defense
La comunidad de seguridad debe evolucionar. La dominancia sistemática de CAI prueba que los CTF Jeopardy ahora sirven solo como tests de regresión para sistemas de IA, no como herramientas de evaluación significativas.
Qué Debe Cambiar
Acciones inmediatas:
- Retirar los CTF Jeopardy a archivos históricos y tests de regresión
- Establecer competiciones Attack & Defense como el nuevo estándar
- Acelerar la adopción defensiva autónoma usando arquitecturas coste-efectivas
Los CTF Attack & Defense introducen elementos adversariales dinámicos que resisten la automatización simple:
- Defensa de servicios en tiempo real
- Gestión adaptativa de parches bajo presión
- Asignación estratégica de recursos
- Capacidades que permanecen únicamente humanas—por ahora
Implicaciones para la Seguridad OT
La dominancia de CAI en Dragos OT CTF conlleva profundas implicaciones para la seguridad de tecnología operacional:
Realidad inmediata (2025-2026): Los entornos OT ya no pueden asumir que las defensas a velocidad humana son suficientes. Las capacidades demostradas indican que los agentes autónomos pueden identificar y explotar vulnerabilidades OT más rápido de lo que los defensores humanos pueden parchearlas.
Esta asimetría demanda la adopción inmediata de sistemas defensivos a velocidad de máquina. Las organizaciones que se aferran a operaciones de seguridad manuales enfrentan compromiso inevitable cuando se confrontan con adversarios potenciados por IA operando a 20× velocidad humana.
El nuevo paradigma de seguridad: Para 2030, las operaciones de seguridad sin agentes de IA serán tan anacrónicas como defender redes sin firewalls.
Arquitectura Técnica: Por qué CAI tiene éxito
La dominancia de CAI proviene de su arquitectura especializada diseñada para operaciones de seguridad IA a escala empresarial:
Componentes Centrales
- Modelo Base: alias1—LLM especializado en seguridad con suscripciones de tokens ilimitados
- Soporte Dinámico: Cambio basado en entropía a modelos SOTA cuando las señales de incertidumbre indican beneficio
- Orquestación Multi-Modelo: Cambio secuencial de modelos con recuento de iteraciones configurable (k)
- Recuperación Mejorada de Errores: Gestión de estado persistente previniendo degradación de rendimiento
- Asignación Adaptativa de Recursos: Delegación inteligente de tareas a través de jerarquía de modelos
Validación de Benchmark
Las evaluaciones CAIBench bajo restricciones estrictas (sesiones de 40 minutos, presupuesto de $10, 300 interacciones) demuestran la amplitud superior de alias1 en resolución de desafíos, particularmente en categorías donde otros modelos luchan.
Esta arquitectura permite a CAI mantener capacidades de ciberseguridad especializadas mientras incorpora selectivamente perspectivas de razonamiento diversas—explicando la velocidad sostenida de 787 pts/hora en Neurogrid mientras los competidores se estrellaban.
Limitaciones y consideraciones éticas
El Problema del Último 5%
A pesar de tasas de resolución del 91-94%, CAI encontró consistentemente desafíos resistentes a la automatización—típicamente involucrando conocimiento cultural/contextual, ofuscación intencionada, o desafíos multi-etapa con dependencias ocultas que requieren intuición humana.
Este patrón sugiere que mientras los CTF Jeopardy están efectivamente resueltos para el 95% de los desafíos, el 5% restante puede preservar algún valor evaluativo.
De la dominancia CTF al despliegue en el mundo real
El abismo entre el rendimiento CTF y la seguridad operacional permanece significativo. Los entornos de producción introducen complejidades ausentes de las competiciones:
- Alertas ambiguas requiriendo contexto de negocio
- Triaje de falsos positivos a escala
- Adversarios que se adaptan en tiempo real
- Información incompleta y fallos en cascada
Riesgos de doble uso y responsabilidad
Las capacidades demostradas de CAI—análisis binario automatizado, fuzzing rápido de protocolos, explotación encadenada—son igualmente aplicables a análisis defensivo y operaciones ofensivas. Nuestro enfoque de despliegue prioriza aplicaciones defensivas mediante protocolos de divulgación responsable.
Cuando los sistemas SOC impulsados por IA toman decisiones automatizadas causando daño, la atribución de responsabilidad se vuelve compleja. Los marcos legales actuales carecen de precedente claro para la responsabilidad algorítmica en contextos de ciberseguridad.
Democratización vs. Proliferación
Los agentes de seguridad autónomos prometen democratizar la experiencia, permitiendo a organizaciones con pocos recursos lograr resultados de seguridad que previamente requerían analistas humanos de élite. Sin embargo, los actores de amenaza sofisticados ya poseen recursos sustanciales.
La democratización defensiva mediante IA ayuda a nivelar un campo de juego ya inclinado en lugar de crear nuevas ventajas ofensivas.
Código abierto, construido en Europa, orientado a defensores
CAI está construido por Alias Robotics desde Vitoria-Gasteiz, potenciado por nuestro modelo especializado en seguridad alias1. Su arquitectura está diseñada para:
- ✅ Operar autónomamente bajo condiciones adversarias
- ✅ Resolver desafíos complejos de seguridad sin intervención humana
- ✅ Integrarse con toolchains modernas de análisis y respuesta
- ✅ Mantener trazabilidad, seguridad y control operacional
- ✅ Alinear con misiones orientadas a defensores
Conclusión: la ventana se ha cerrado
El circuito CTF 2025 entregó un veredicto inequívoco: los métodos de evaluación tradicionales han quedado obsoletos. La conquista sistemática de CAI—cinco competiciones principales, premio de $50.000, tasas de resolución del 91%, reducción de costes del 98%—prueba que estos formatos ahora miden solo velocidad computacional, no experiencia en seguridad.
Las organizaciones ya no pueden reclamar el coste como razón para retrasar la adopción de IA en operaciones de seguridad. La excusa económica para la inacción ya no existe.
El camino a seguir es desafiante pero claro:
- Repensar el significado de los CTF Jeopardy—ahora sirven solo como tests de regresión para IA
- Establecer Attack & Defense como el nuevo estándar para evaluación significativa
- Acelerar la adopción de sistemas defensivos autónomos usando arquitecturas coste-efectivas
En la batalla entre capacidades humanas y de máquina para tareas de seguridad estandarizadas, las máquinas ya han ganado varias rondas—de manera asequible.
La ventana para la transición gradual se ha cerrado.
Comienza con CAI
📦 Instala dependencias (pip install -e .)
⚙️ Configura .env (claves LLM, ajustes del modelo)
🚀 Lanza con cai
🤖 Comienza a probar tu postura de seguridad
Esta investigación fue parcialmente financiada por el proyecto acelerador del Consejo Europeo de Innovación (EIC) "RIS" (GA 101161136).
Artículos Relacionados: